 博弈论与经济分析完全信息动态Word下载.docx
博弈论与经济分析完全信息动态Word下载.docx
- 文档编号:5800672
- 上传时间:2023-05-05
- 格式:DOCX
- 页数:21
- 大小:155.10KB
博弈论与经济分析完全信息动态Word下载.docx
《博弈论与经济分析完全信息动态Word下载.docx》由会员分享,可在线阅读,更多相关《博弈论与经济分析完全信息动态Word下载.docx(21页珍藏版)》请在冰点文库上搜索。
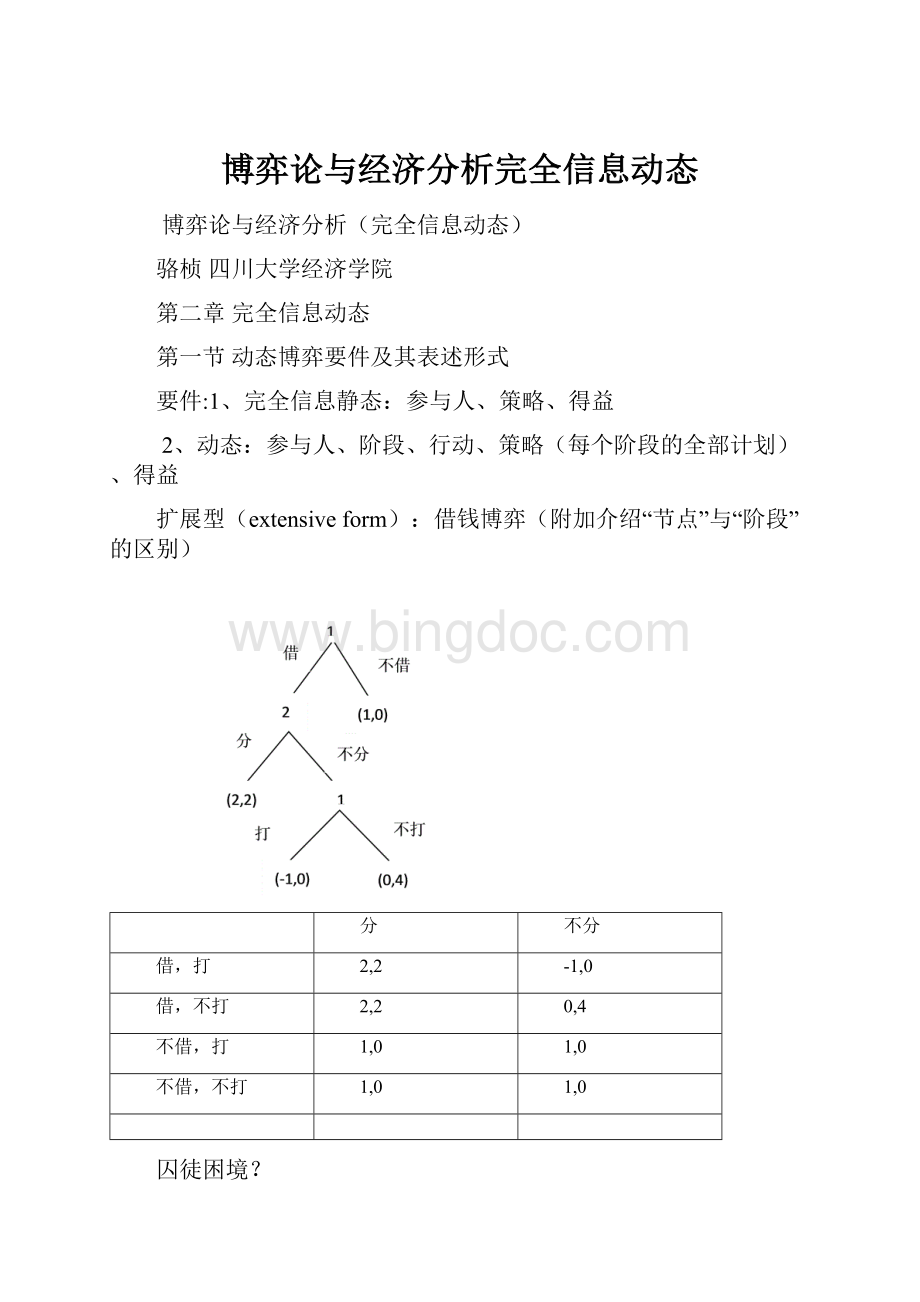
(和后面顺序归纳法对比,为什么这里不存在顺序归纳法的解)
子博弈与子博弈完美纳什均衡(SPNE):
一个不正式的说明:
子博弈:
由一个动态博弈第一个阶段以外的某个阶段开始的后续博弈构成的,有初始信息集和进行博弈所需要的全部信息,能够自成一个博弈的原博弈的一部分。
SPNE:
如果一个策略组合在整个动态博弈和所有子博弈中都构成NE,那么这个策略组合称为该动态博弈的SPNE。
(注意,构成SPNE的策略中,很多节点的行为不在“均衡路径”上,简单介绍“均衡路径”)
SPNE是对动态博弈中多个NE进行精炼。
例子:
1、两阶段动态完全且完美信息动态博弈
该类模型的一般性描述:
(i)参与人1从可行集A1中选择行动a1(为什么不是s1了?
注意“策略”在动态博弈中含义的变化)
(ii)参与人2观察到a1之后从可行集A2中选择行动a2
(iii)两人的收益分别为u1(a1,a2)和u2(a1,a2)
完全且完美信息动态博弈的特点:
行动是顺序发生的;
下一步选择之前,所有以前的行动都是可以被观察到的;
每一可能的行动组合下参与者的收益都是共同知识。
求解方法:
逆向归纳
当参与人2行动时,能看见参与人1的选择,于是
假定A1中的每一个a1,参与人2的最优化问题只有唯一解,用其反应函数表示R2(a1)。
因为参与人1能像参与人2一样解出这个问题,因此他能预测到2的反应,于是
假定这个规划也有唯一的解
,我们称
是这一博弈的逆向归纳解。
(后面我们将严格定义子博弈完美纳什均衡,只有不含不可置信威胁的NE才是SPNE)
例1:
斯塔克伯格模型
古诺模型中,一个企业作为领导者先行选择(伯川德模型的先后选择作为习题):
企业1选择产量q1,企业2观察到产量q1,选择产量q2,企业i的利润由以下函数给出:
其中
,且
(先行者优势;
如果存在先后顺序,但是企业2观察不到q1,退化为古诺模型,为什么?
)
按照逆向归纳的思路,先考虑企业2在看到企业1的任意产量之后的最优反应:
由一阶条件(二阶条件略)可得:
厂商1预计到厂商2会做这样的反应,于是,在第一阶段厂商1最优化的问题则变成:
代入可得
代入求得
,这是先行者优势的体现。
例2:
有工会企业的工资和就业
例3:
讨价还价模型
1、三回合
2、无限回合(一个非正式的讨论)
结论和三回合对比,1不再具有强制性“优势”
为什么一定要用三阶段?
(或者说奇数阶段,偶数,比如2或者4不行吗?
例4:
委托代理模型
(i)无不确定性
委托人选择提供一份怎样的合同{W(E),W(S)};
代理人选择接不接受这份合同,然后选择“努力”E还是“偷懒”S。
因为没有不确定性,所以产出是代理人努力的函数R(E)或者R(S).
完全且完美信息,进行逆向归纳:
若W(E)-E>
W(S)-S,则代理人会选择努力,这个条件称为“激励相容约束”
而上一阶段代理人是否会接受呢?
0则代理人会接受,这个条件称为“参与相容约束”
当然,需要R(E)-W(E)>
R(0)委托然才选择委托。
(ii)有不确定性但可监督
努力与否可以看得到并可证实,则通常工资取决于代理人的努力而不是工作成果。
这样一来,若产出除了代理人的努力之外还存在着不确定性,那么风险就由委托人全部承担。
即风险仅影响委托人的行为,不影响代理人的行为。
假设R(0)=0,并引入“自然”参与者0来表示风险。
假设有10和20两种可能的产出。
因为风险不影响代理人的行为,则
W(S)-S,则代理人会选择努力“激励相容约束”
0则代理人会接受“参与相容约束”
因为存在风险,委托人要参与则其期望得益必须大于0.
(iii)有不确定性且不可监督
无法依照代理人的努力与否发工资,只能参照工作成果发工资。
但是工作成果不仅仅取决于代理人的努力,还存在一定的风险。
此时,激励相容约束变为:
0.9[W(20)-E]+0.1[W(10)-E]>
0.1[W(20)-S]+0.9[W(10)-S]
而参与相容约束则变成:
而对于委托人而言,必须满足以下不等式,他才会选择参与:
0.9[20-W(20)]+0.1[10-W(10)]>
在满足上述条件下,委托人最小化期望工资的指出,从而设计“薪酬制度”:
可作为作业……
(iv)一个连续型选择的例子:
假设代理人有正的机会成本
而且努力的负效用是努力水平的单调递增的凸函数C=C(e)。
代理人选择的努力水平e是连续的,产出是e的随机函数R=R(e),由于具有不确定性且不能监督,则只能依据R支付报酬,w=w(R)=w(R(e))。
于是,代理人得益为w-C=w[R(e)]-C(e)
委托人得益为R-w=R(e)-w[R(e)]
根据逆向归纳的思路:
参与相容约束为:
w[R(e)]-C(e)
激励相容约束:
委托人最满意的努力水平e*符合代理人的利益最大化,即
w[R(e*)]-C(e*)>
=w[R(e)]-C(e)任意e
委托人在以上两个约束下选择工资方案最大化自己的收益。
比如:
R(e)=4e+η,η是均值为0的随机扰动项。
=1
C(e)=e2
w[R(e)]=A+B[R(e)]并且委托人、代理人风险中性
则,委托人的收益为R(e)-w[R(e)]=4e+η-A-B[4e+η]期望得益为4(1-B)e-A
代理人的收益为w[R(e)]-C(e)=A+B[4e+η]-e2期望得益为A+B4e-e2
问题是:
委托人如何确定A和B来最大化自己的收益。
A+B4e-e2>
激励相容约束为:
e*=2B
首先,委托人要尽量压低工资,但是最低必须满足参与相容约束,于是不等式取等号
有:
A+B4e-e2=1即A+B4e=1+e2
将其带入委托人收益函数中,为4e-e2-1最大化一介条件可确定委托人满意的努力程度为e*=2,从而B=1,带入可求A=-3
承包制
第三节有同时选择的动态博弈(完全但不完美信息)
该类模型的一般描述:
1、参与者1、2同时从各自的可行集A1和A2中选择行动a1、a2.
2、参与者3、4观察到第一阶段的结果,从各自的可行集A3和A4中选择行动a3、a4
3、收益为ui(a1,a2,a3,a4)i=1,2,3,4
求解:
逆向归纳法的思路
为简化分析,我们假设对于第一阶段博弈的每一个可能的结果(a1,a2),第二阶段有唯一的NE,a3*(a1,a2)以及a4*(a1,a2)。
当然,参与人1、2会预测到这一点,以选定最优策略a1*,a2*
于是,以上博弈的子博弈完美纳什均衡为(a1*,a2*,a3*(a1*,a2*),a4*(a1*,a2*))
银行挤兑模型
不存在贴现
提款
不提
r,r
D,2r-D
2r-D,D
下一阶段
R>
D>
r>
D/2
R,R
2R-D,D
D,2R-D
逆向归纳的思路:
关税和国际市场的不完全竞争
博弈的顺序:
(1)政府同时选择关税税率t1和t2
(2)企业观察到关税税率后同时选择其提供国内消费和出口的产量(h1,e1)和(h2,e2)
(3)企业i的收益为利润,政府i的收益为本国总福利,包括本国消费者剩余、本国企业利润、以及政府从他国企业j所收取的关税。
若i国市场上总供给为Qi,则市场价格为pi(Qi)=a-Qi;
i国企业为国内市场生产hi并出口ei,于是Qi=hi+ej;
企业的边际成本为常数c,于是总成本为Ci=c(hi+ei);
若政府j的关税税率为tj,则i国企业向j国出口ej,则必须支付ei*tj的关税。
(最终的SPNE为什么是低效率的?
工作竞赛(竞标赛制度)
为同一个老板工作的两个工人,工人i(i=1,2)的产出为yi=ei+εi,其中ei为努力程度,εi为随机扰动项。
博弈顺序如下:
(1)工人同时选择非负的努力水平ei>
=0
(2)随机扰动项εi相互独立并服从均值为0,密度函数为f(ε)的概率分布
(3)工人的努力程度不可观测,但是产出是可观测的
老板为了激励员工,在他们中间开展工作竞赛,优胜者获得工资wH失败者获得工资wL。
工人的效用为u(w,e)=w-g(e),其中g(e)表示努力带来的负效用,g’>
0,g”>
老板收益为y1+y2-wH-wL
解:
逆向归纳法:
(1)第二阶段:
给定工资策略,工人选择努力水平最大化自己的期望得益:
f.o.c
“激励相容约束”(忽略角解)
因为工人的条件是对称,所以
,从而
于是“参与相容约束”可写做:
(2)第一阶段:
老板要设定工资水平,在满足以上两个条件的前提下,最大化自己的期望得益
,于是“参与相容约束”变为:
于是,老板的期望利润可写成
,因此,老板合意的努力程度是最大化其收益的,一阶条件为
。
求出e*,根据两个条件可求出W的方案。
第四节子博弈和SPNE的理论探讨
定义:
一个博弈的扩展型表述包括:
(1)参与者(2a)每一参与者在何时行动(2b)每次轮到某一参与者行动时,可供其选择的行动(2c)每次轮到某一参与者行动时,他所了解的信息(3)参与者可能选择的每一行动组合对应的参与者的收益。
参与者的策略是关于行动的一个完整的计划,即每一种可能情况下的可行的选择。
参与人有4个策略:
2
1
L’,L’
L’,R’
R’,L’
R’,R’
L
3,1
1,2
R
2,1
0,0
参与者的一个信息集指满足以下条件的节点的集合:
(1)在此信息集中的每一个节点都轮到该参与者行动
(2)当博弈论进行到信息集中的某一个节点,应该行动的参与者并不知道到达了哪个节点。
扩展型博弈的子博弈:
(1)始于单节信息集的决策节
(2)包含博弈树中该节点一下的所有决策节和终节点
(3)没有对任何信息集形成分割。
如果参与者的策略在每一个子博弈中都构成纳什均衡,则称纳什均衡是子博弈完美的。
定理:
任何有限的完全信息动态博弈都存在子博弈完美纳什均衡(也许是混合策略的)。
证明思路:
本身及其每个子博弈都可表示成扩展型。
区分均衡和解:
两阶段完全且完美信息动态博弈中,逆向归纳解为(a1*,R2(a1*)),但其子博弈完美纳什均衡为(a1*,R2(a1))
前面完全非完美信息两阶段博弈中,子博弈完美解为(a1*,a2*,a3*(a1*,a2*),a4*(a1*,a2*)),但其子博弈完美纳什均衡为(a1*,a2*,a3*(a1,a2),a4*(a1,a2))
求NE,逆推解以及SPNE
扩展:
颤抖手均衡
顺推归纳法
蜈蚣博弈
第三章重复博弈
对某一博弈重复进行(不一定要静态的):
比如天天买菜,或者长期合作,所谓“老主顾”。
两阶段重复博弈:
参与者2
参
与
者
L2
R2
L1
1,1
5,0
R1
0,5
4,4
逆向归纳法,将第二阶段唯一NE的得益“简单”加到第一阶段去,得第一阶段的博弈为:
6,1
1,6
5,5
(L1,L2)是该重复博弈的唯一的NE,合作解(R1,R2)是无法实现的。
对给定阶段博弈G(解释一下什么是阶段博弈),令G(T)表示G重复T次的有限重复博弈,并且在下一次博弈开始前,所有以前进行的博弈都能被观测到。
G(T)的收益为T次阶段博弈收益的简单相加。
如果阶段博弈G有唯一的NE,则对任意有限的T,重复博弈G(T)有唯一的子博弈完美纳什均衡:
即G的NE在每阶段重复进行。
这里阶段博弈G为完全信息动态时,结论依然成立。
若G是完全且完美信息动态博弈且只有唯一的逆向归纳解,则G(T)有唯一的子博弈完美纳什均衡,即每阶段其逆向归纳解重复进行。
类似的,若G是上章中的完全不完美信息动态博弈,且有唯一的子博弈完美纳什均衡,则G(T)也有唯一的子博弈完美纳什均衡:
G的子博弈完美纳什均衡重复进行T次。
上述模型变形:
(和前面很像,注意区别在于不是唯一的纳什均衡)G为
M2
0,0
M1
3,3
触发策略:
对参与人i,若第一阶段策略组合为(M1,M2)则第二阶段选择(R1,R2);
否则,在第二阶段选择(L1,L2)
我们逆推回第一阶段,总得益为两次博弈得益的简单相加:
7,7
这说明,这样的“触发策略”是NE,同时,第二阶段选(R1,R2)是NE,于是该触发策略是该两阶段重复博弈的“子博弈完美纳什均衡”。
当然,这个博弈不止一个SPNE。
该例主要说明:
对将来行动所作的可信的威胁或承诺可以影响到当前的行为。
于是,“合作”即使不是NE,也可能出现在SPNE中。
但是这里也说明子博弈完美对于“可置信”的要求并不严格。
因为如果第一阶段没有出现合作,那么第二阶段(R1,R2)仍是可选择的纳什均衡,似乎一切都过去了,再选择(L1,L2)有点愚蠢。
参与双方出现重新谈判似乎是很自然的事情,从而两阶段之间出现了“交流”,若“重新谈判”允许,则应该考虑在分析中,若不允许,也可能出现在参与人对局势的分析中。
P2
Q2
P1
4,1/2
Q1
1/2,4
不仅惩罚,还奖励了惩罚者。
无限重复博弈
在无限重复博弈中有一个更强的结论:
即使阶段博弈只有唯一的NE,无限重复博弈中也可以存在子博弈完美纳什均衡,其中没一个阶段的结果是G的NE。
定义给定贴现因子δ(δ=1/(1+r),r为利率),无限收益序列π1,π2,π3……的现值为
借助贴现因子,我们可以把无限重复博弈解释称为一个随机结束的有限重复博弈。
(毕竟无限重复并不现实,可以想一想为什么需要随机结束?
)假设博弈每一阶段结束的概率为p,继续博弈的概率为1-p,假设每阶段的收益为π,则博弈进行前,期望收益为(1-p)π/(1+r),贴现率δ=(1-p)/(1+r)
回到博弈:
参与者i的触发策略:
在第一阶段选择Ri,且在第t阶段,如果所有前面t-1阶段的结果都是(R1,R2),则选择Ri,否则选择Li。
首先要证明如果δ足够接近1,该策略是无限重复博弈的纳什均衡,再证明这一纳什均衡是子博弈完美的。
为了证明上述触发策略对博弈双方而言都是纳什均衡,我们假设参与者i已经采取触发策略,可以证明在δ足够接近1的条件下,参与者j的最优反应也选择同样的策略。
如果选择“不合作”,现值为
如果选择“合作”,现值为
当且仅当
时,“合作”才是最优的。
于是当δ>
=1/4时,采取触发策略是纳什均衡。
接下来证明这一纳什均衡是子博弈完美的,这需要重新界定一下相关概念。
定义给定一个阶段博弈G,令G(∞,δ)表示相应的无限重复博弈。
对于每个t,之前的t-1次阶段的博弈结果在t阶段开始之前都可被观测到,每个参与者在G(∞,δ)中的收益为无限次博弈中每一阶段得益的现值。
定义在重复博弈G(T)或无限重复博弈G(∞,δ)中,参与者的一个策略指在每一个阶段,针对其前面所有可能的结果,参与者会选择的行动。
定义在有限重复博弈G(T)中,由第t+1阶段开始的一个子博弈为G进行T-t次的重复博弈,可表示为G(T-t)。
在无限重复博弈G(∞,δ)中,由第t+1阶段开始的每个子博弈都等同于初始博弈G(∞,δ)。
博弈G(∞,δ)到t阶段为止有多少不同的可能进行过程,就有多少从t阶段开始的子博弈。
那么,G(∞,δ)中的子博弈分为2类:
一是之前的结果都是(R1,R2)……;
二是至少有一个结果不是(R1,R2)……从而可以证明……
无名氏定理(Freedman,1971)令G为一个有限的完全信息静态博弈,令(e1,…,en)表示G的一个NE下的收益,且(x1,…,xn)表示G的任意可行收益。
如果对每个参与者i有xi>
ei,且如果δ足够接近1,则无限重复博弈G(∞,δ)存在一个子博弈完美纳什均衡其平均收益可以达到(x1,…,xn)。
解释什么是可行收益,什么是平均收益
1、双寡头古诺模型中的共谋
市场总供给为:
Q=q1+q2,市场价格为P(Q)=a-Q,假定Q<
a,企业边际成本为c,没有固定成本,同时选择产量。
无限次重复,贴现率为δ。
合作的触发策略及其条件:
在第一阶段生产垄断产量的一半
;
在第t阶段,若前面t-1阶段两个企业产量都为
,则继续生产
否则,生产古诺均衡时的产量。
根据前面的计算,我们可知:
当双方都生产
的时候,各获得利润
当双方都生产古诺产量
时,各获得利润
若一方生产
,另一方偏离约定,最大化当期利润的产量为
,所能获得的利润为
要使得上述触发策略成为纳什均衡,必须满足以下条件:
带入
、
计算可得
若δ<
9/17……
δ较小,如何实现合作?
(胡萝卜加大棒)
2、效率工资
阶段博弈:
1、企业开出工资水平w。
2、工人接受或者拒绝。
若拒绝了w就成为自我雇佣,获得w0,。
3、若接受,工人选择努力或者是偷懒。
4、企业无法观测工人是否努力,但是能观测产出。
5、努力一定获得高产出y>
0,偷懒以p的概率获得高产出,1-p的概率获得低产出0.
收益:
企业y-w,工人w-e,若工人偷懒,e=0,若出现低产量y=0.
假定:
y-e>
w0>
py
阶段博弈的纳什均衡
触发策略及其条件
3、货币政策的时间一致性问题
1、雇主选择一个通胀的预期πe
2、货币当局观测到这一预期,并选择真实通胀率π。
雇主:
-(π-πe)2
货币当局:
U(π,y)=-cπ2-(y-y*)2
对收益函数作说明:
y=by*+d(π-πe)
阶段博弈的SPNE:


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 博弈论 经济 分析 完全 信息 动态
 冰点文库所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰点文库所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 整编新型生态农业旅游休闲农庄项目发展建设市场研究报告.docx
整编新型生态农业旅游休闲农庄项目发展建设市场研究报告.docx
-
证券投资顾问业务暂行规定.docx
-
知识产权法司法考试历年真题及答案解析.docx
-
职业道德的复习重点.docx
-
志愿者活动心得精选多篇.docx
-
治理雾霾应重视大气静电学说.docx
-
中国成人脑死亡判定标准与操作规范第二版.docx
-
中国名牌产品申请表.docx
-
中国纸板产业深度调研及产业投资评估报告.docx
-
中考化学考点分类解析导学案14第3讲碳和碳的氧化物1碳单质的物理性质和用途.docx
-
中学学年度第二学期学校工作计划.docx
-
中英文安全标语word版本 26页.docx
-
重庆市高考英语试题.docx
-
注册安全工程师《安全生产管理知识》真题及答案.docx
-
装机必备硬件基础知识再接再厉完成装机.docx
-
子部.docx
-
总结范文骨干教师培训总结15篇.docx
-
最新 Marlin固件全中文解析.docx
-
最新部编版三年级语文上册第24课《司马光》教学设计.docx
-
最新二年级数学上册寒假作业全面系统146.docx
-
最新猴年祝贺词大全 精品.docx
-
最新入党思想报告3000字范文思想汇报文档五篇.docx
-
《OTL功率放大器的制作与调试》项目教学设计方案.docx
-
《化学方程式》单元检测2.docx
-
中考语文阅读精品题.docx
-
工伤司法鉴定标准是怎样的.docx
-
公共事务管理硕士在职专班入学研究计画书.docx
-
公考必备《行测》数量关系题库.docx
-
股票技术指标详解二.docx
-
人教版数学六下第二单元《百分数二》word教案精品教案.docx
-
简大型机房建设系统全套设计方案.docx
-
建筑工程基础加固与纠偏处理应用探讨.docx
-
山东省烟台龙口市六年级生物下学期期中试题五四制.docx
-
维规规定各设备检维修周期DOC.docx
-
小学五年级开学计划.docx
-
卫生检验员技术工作总结.docx
-
小学写字教学心得.docx
-
未完成罪研究陈兴良.docx
-
陕西省初中生综合素质评价实施办法.docx
-
文献综述.docx
-
商铺抵押合同范本工作范文.docx
-
人教版化学知识集萃.docx
-
西师版小学四年级数学下册第四单元三角形单元测试题.docx
-
商业地理学.docx
-
人文科学系法律经济学论论动产的善意取得制度.docx
-
人教版九年级中考化学专题原子的有关数量计算练习题.docx
-
校园志愿者活动策划书.docx
-
销售上路培训课程.docx
-
写经济担保书范文.docx
-
人教版六年级英语上册recycle1.docx
-
新版XX产业园区标准厂房建设项目可行性研究报告.docx
