 LSGAN(LeastSquaresGenerativeAdversarialNetworks).pdf
LSGAN(LeastSquaresGenerativeAdversarialNetworks).pdf
- 文档编号:18633136
- 上传时间:2023-08-23
- 格式:PDF
- 页数:3
- 大小:271.40KB
LSGAN(LeastSquaresGenerativeAdversarialNetworks).pdf
《LSGAN(LeastSquaresGenerativeAdversarialNetworks).pdf》由会员分享,可在线阅读,更多相关《LSGAN(LeastSquaresGenerativeAdversarialNetworks).pdf(3页珍藏版)》请在冰点文库上搜索。
LSGAN(LeastSquaresGenerativeAdversarialNetworks)1.前传统GAN出现的问题:
传统GAN,将Discriminator当作分类器,最后层使Sigmoid函数,使交叉熵函数作为代价函数,容易出现梯度消失和collapsemode等问题,具体原因参考本博客。
LSGAN主要解决关键:
使最乘损失代替交叉熵损失,解决了传统GAN成的图质量不以及训练过程不稳定这俩个缺陷。
为什么使最乘法能够改善传统GAN存在的问题?
1.避免梯度消失章指出,传统的GAN在使成的“fake”图(已被Discriminator分类为正样本)来更新Generator的参数的时候,会造成梯度消失,尽管该成的fake图数据离真实样本的数据还有定的距离。
当使最乘来作为Discriminator的代价函数的时候,最乘会将成的“fake”图拉向决策边界,这的决策边界穿过真实样本,可以使得LSGANs成的图更接近真实的数据。
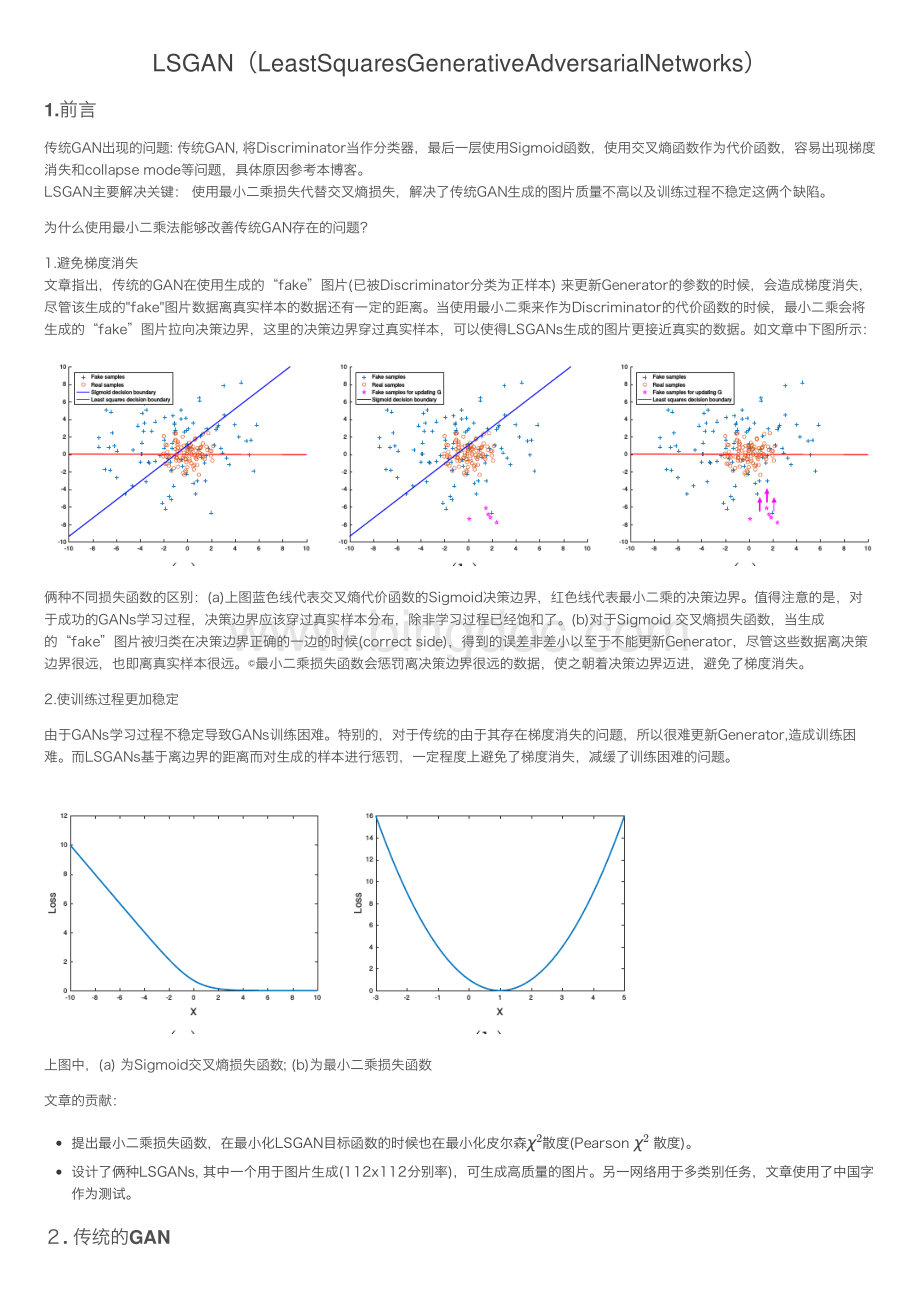
如章中下图所:
俩种不同损失函数的区别:
(a)上图蓝线代表交叉熵代价函数的Sigmoid决策边界,红线代表最乘的决策边界。
值得注意的是,对于成功的GANs学习过程,决策边界应该穿过真实样本分布,除学习过程已经饱和了。
(b)对于Sigmoid交叉熵损失函数,当成的“fake”图被归类在决策边界正确的边的时候(correctside),得到的误差差以于不能更新Generator,尽管这些数据离决策边界很远,也即离真实样本很远。
最乘损失函数会惩罚离决策边界很远的数据,使之朝着决策边界迈进,避免了梯度消失。
2.使训练过程更加稳定由于GANs学习过程不稳定导致GANs训练困难。
特别的,对于传统的由于其存在梯度消失的问题,所以很难更新Generator,造成训练困难。
LSGANs基于离边界的距离对成的样本进惩罚,定程度上避免了梯度消失,减缓了训练困难的问题。
上图中,(a)为Sigmoid交叉熵损失函数;(b)为最乘损失函数章的贡献:
提出最乘损失函数,在最化LSGAN标函数的时候也在最化尔森散度(Pearson散度)。
设计了俩种LSGANs,其中个于图成(112x112分别率),可成质量的图。
另络于多类别任务,章使了中国字作为测试。
.传统的GAN22GAN的学习过程即同时训练Discriminator(D)和Generator(G)的过程,从斯分布的变量,学习潜在变量,来产分布,使得该分布与真实分布越接近越好。
因此,学习的是个映射过程,通过变量映射空间来产分布。
另,是个分类器,来判断产的分布是否与真实样本接近,通过变量空间判断是否样,同样的也是个映射。
传统GAN的代价函数如下:
(公式1)这稍微解释下:
整个式由两项构成。
表真实图,表输络的噪声或者斯分布数据,表络成的图。
表络判断真实图是否真实的概率(因为就是真实的,所以对于来说,这个值越接近1越好)。
是络判断成的图的是否真实的概率。
的的:
是络判断成的图是否真实的概率,应该希望成的图“越接近真实越好”。
也就是说,希望尽可能得,这时会变。
因此我们看到式的最前的记号是。
的的:
的能越强,应该越,应该越。
这时会变。
因此式对于来说是求最(max_D).LeastSquaresGenerativeAdversarialNetworksLSGANs在Discriminator上使a-b编码策略,简单来说就是a来代表“fake”数据,b来代表“real”数据。
LSGANs的标函数为:
(公式2)其中c代表成器为了让判断器认为成的数据是真实分布数据定的值。
在章中作者设置。
同时在章中,作者列出了传统的GAN其实在优化的是JS散度,具体参考,(公式3)化为JS散度为因此当俩个分布没有重叠或者重叠部分可忽略的时候,,因此此时的梯度就变为0了。
因此,对于作者提出的LSGANs,研究了LSGANs损失函数和f散度(f-divergence)之间的联系:
公式(4)其中在添加并不会影响优化过程,因为添加的项没有包含关于的内容。
对求导数因此对于公式4,我们可以得到(公式6)这是在iscriminator达到最优的时候,Generator的损失函数,如果设和的话,有:
zgpgGz;(g)Dx;(d)minmaxV(D,G)=GDGANElogD(x)+xp(x)dataElog(1zp(z)zD(G(z)xzGG(z)GD(x)DxDD(G(z)DGGD(G(z)DGGGD(G(z)V(D,G)minGDDD(x)D(G(x)V(D,G)DminV(D)=DLSGANE(D(x)b)+21xp(x)data2E(D(G(z)a)21zp(z)z2minV(G)=GLSGANE(D(G(z)c)21zp(z)z2a=c=1,c=0C(G)=KLp+(data2p+pdatag)KLp(g2p+pdatag)log(4)2JSPP(datag)2log2JSPP=(datag)0minV(D)=DLSGANE(D(x)b)+21xp(x)data2E(D(G(z)a)21zp(z)z2minV(G)=GLSGANE(D(x)c)+21xp(x)data2E(D(G(z)c)21zp(z)z2V(G)LSGANE(D(x)c)xp(x)data2D(x)=p(x)+p(x)datagbp(x)+ap(x)datag2C(G)=ED(x)c+xpd()2ED(x)cxpg()2=Ec+xpd(p(x)+p(x)dgbp(x)+ap(x)dg)2Ecxpg(p(x)+p(x)dgbp(x)+ap(x)dg)2=p(x)dx+Xd(p(x)+p(x)dg(bc)p(x)+(ac)p(x)dg)2p(x)dxXg(p(x)+p(x)dg(bc)p(x)+(ac)p(x)dg)2=dxXp(x)+p(x)dg(bc)p(x)+(ac)p(x)(dg)2=dxXp(x)+p(x)dg(bc)p(x)+p(x)(ba)p(x)(dg)g)2bc=1ba=2其中为Pearsondivergence(尔森散度),因此在最优化的情况下将优化变为了Pearsondivergence,避免了使JS散度下造成的梯度为0,其中需要满b-c=1且b-a=2。
.搭建的络俩种参数的选择:
(公式8)和(公式9)但是作者在章提了,这俩种参数在实践中的性能基本样。
具体实验结果可看原2C(G)=dxXp(x)+p(x)dg2p(x)p(x)+p(x)(g(dg)=p+p2pPearson2(dgg)Pearson222minV(D)=DLSGANE(D(x)1)+21xp(x)data2E(D(G(z)+1)21zp(z)z2minV(G)=GLSGANE(D(G(z)21zp(z)z2minV(D)=DLSGANE(D(x)1)+21xp(x)data2E(D(G(z)21zp(z)z2minV(G)=GLSGANE(D(G(z)1)21zp(z)z2


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- LSGAN LeastSquaresGenerativeAdversarialNetworks
 冰点文库所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰点文库所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 “安全培训随机抽查”管理制度.doc
“安全培训随机抽查”管理制度.doc
-
“爱学习爱劳动爱祖国”主题班会教案.doc
-
“遨游汉字王国”综合性学习活动方案.doc
-
“费马点”与中考试题.doc
-
“的、地、得”区分技巧及100练习题(附答案).docx
 “代位求偿”案件索赔申请书(责任对方为机动车方)【范文】.xls
“代位求偿”案件索赔申请书(责任对方为机动车方)【范文】.xls
-
“525心理健康节心理健康活动”活动策划书.docx
-
“厂中厂”安全生产管理协议书.docx
-
“抖音同城获客码”商家管理系统销售合同.docx
-
“磁铁”单元项目式学习设计.docx
-
“富山海”轮与“GDYNIA”轮碰撞事故调查报告.doc
-
“525“大学生心理健康日系列活动策划书(通用8篇).docx
-
“不唯上、不唯书、只唯实”学习心得体会.docx
-
“的地得”的用法及练习.doc
-
“的地得”100题附答案.doc
-
“奥特曼”崇拜在幼儿德育中的运用.doc
-
“分数乘整数”课堂实录与评析.doc
-
“弘扬民族精神凝聚抗疫力量”非连续性文本阅读训练及答案.docx
-
“囚徒困境”视角下我国的食品安全问题分析.doc
-
“三个课堂”教学工作安排.docx
-
“文明校园拒绝欺凌”主题班会设计教案.docx
-
《“8”字跳长绳》教案.doc
-
“互联网+教育”调查问卷.docx
-
“平安校园”主题班会教案.doc
-
“书香墨韵”读书节活动方案.docx
-
“文明礼仪伴我行”演讲比赛活动方案.doc
-
“养成良好卫生习惯”活动方案.doc
-
“胖东来”的发展现状分析.doc
-
“职业高原”现象分析与应对策略.doc
-
《CAD制图》教学大纲.doc
-
“快乐”主题班会活动设计教案.docx
-
“使用与满足理论”视角下的移动短视频研究——以抖音App为例.docx
-
甘肃省阿克塞哈萨克族自治县高二上学期期中考试语文试题.docx
-
高标准基本农田整治项目监理规划及细则.docx
-
扶贫开发工作先进事迹材料与技师年终工作总结4篇汇编.docx
-
干部老年科业务学习培训记录.docx
-
服装店开业活动方案完整版.docx
-
钢骨柱安装施工方案.docx
-
改写句子 同义句转换160个 人教版.docx
-
钢结构创优要求及保证措施.docx
-
福建省永安市第三中学学年高二英语下学期期初综合检测试试题2含答案 师生通用.docx
-
高级英语词汇汇总第一册.docx
-
感恩励志快乐学习主持稿范文.docx
-
高层住宅剪力墙钢筋位置施工工法.docx
-
复合墙板安装施工组织方案.docx
-
高二生物会考复习练习题必修二 2.docx
-
富士康电脑手机制造废气处理方案1.docx
-
高级英语第三版爱情就是谬误课文翻译.docx
-
钢铁是怎样炼成的十八章详细检测附答案.docx
-
高考生物二轮复习专题二代谢串讲二细胞呼吸与光合作用课时作业34大题练.docx
-
感恩教师节明信片祝福寄语.docx
链接地址:https://www.bingdoc.com/p-18633136.html
